


自注意力机制中的MHA/MQA/GQA
本文最后更新于 2024-06-11,文章内容可能已经过时。
1、MHA
MHA (Multi-Head Attention):
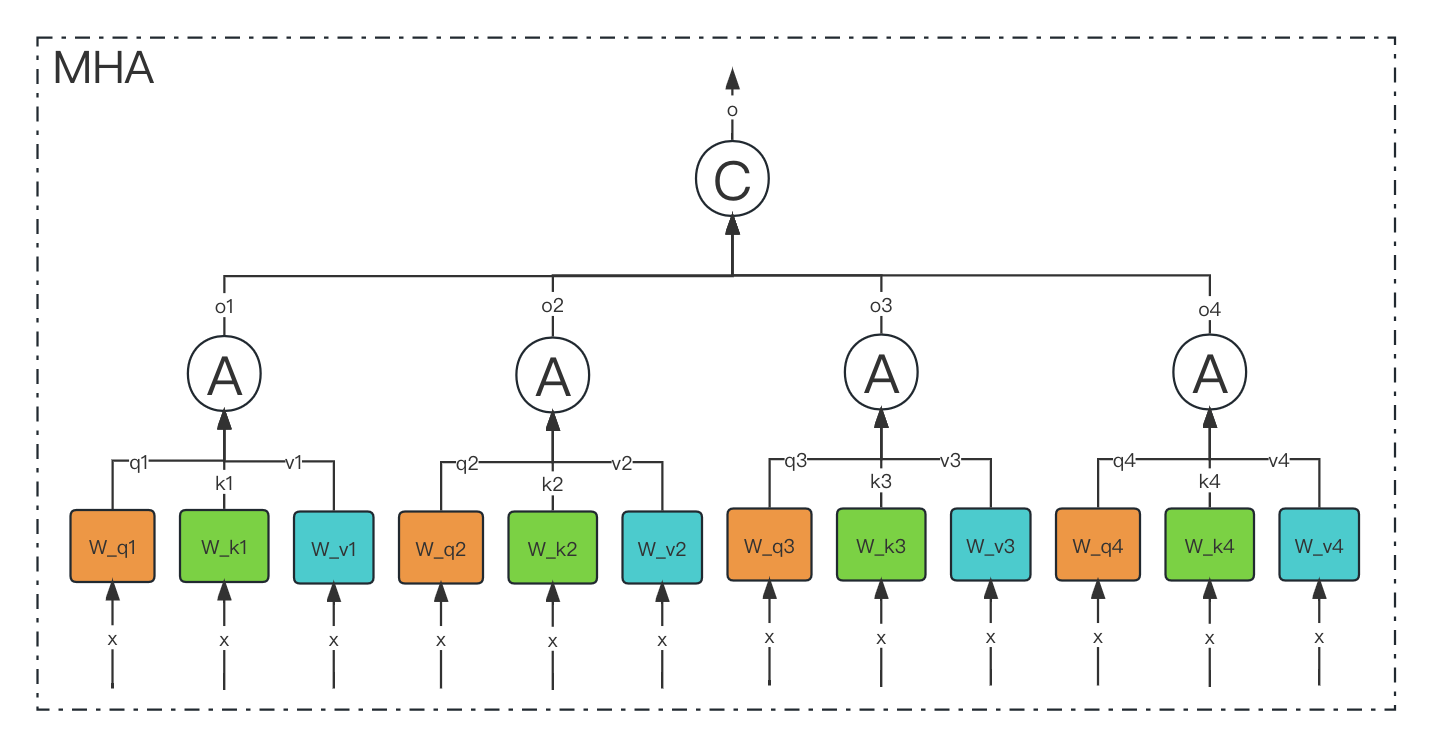
MHA 是 "Multi-Head Attention" 的缩写。它是一种注意力机制,通常用于处理序列数据,如自然语言文本。在 MHA 中,输入序列被分成多个头(head),每个头都可以关注输入序列的不同部分。这些头并行运算,然后结果被组合以生成最终的输出。MHA 可以捕捉输入序列中的不同关系和依赖关系,被广泛用于诸如机器翻译、文本摘要等自然语言处理任务中。
2、MQA
MQA (Multi-Query Attention)
论文地址📰:https://arxiv.org/pdf/1911.02150.pdf
MQA 是 19 年提出的一种新的 Attention 机制,其能够在保证模型效果的同时加快 decoder 生成 token 的速度。
我们知道,在 transformer 中是包含若干个注意力头(head)组成的,
而每个 head 又是由: query(Q),key(K),value(V) 3 个矩阵共同实现的。
MQA 让所有的头之间 共享 同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
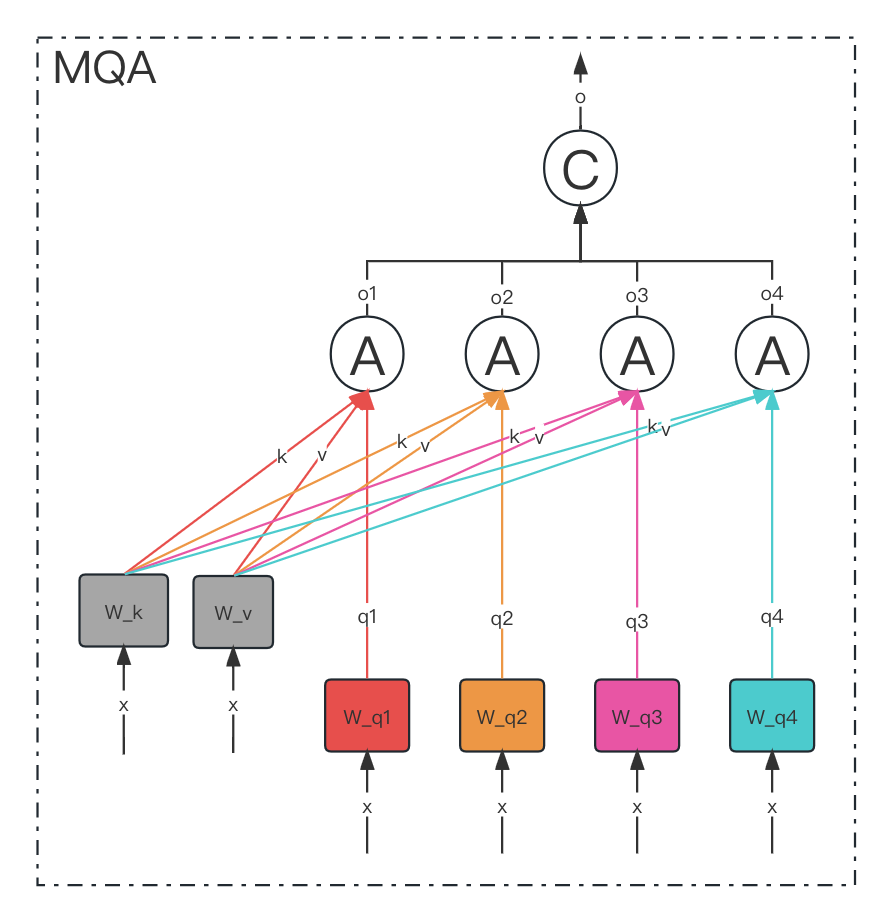
MQA 实际上是将 head 中的 key 和 value 矩阵抽出来单独存为一份共享参数,
而 query 则是依旧保留在原来的 head 中,每个 head 有一份自己独有的 query 参数。
3、GQA
GQA (Group Query Attention)
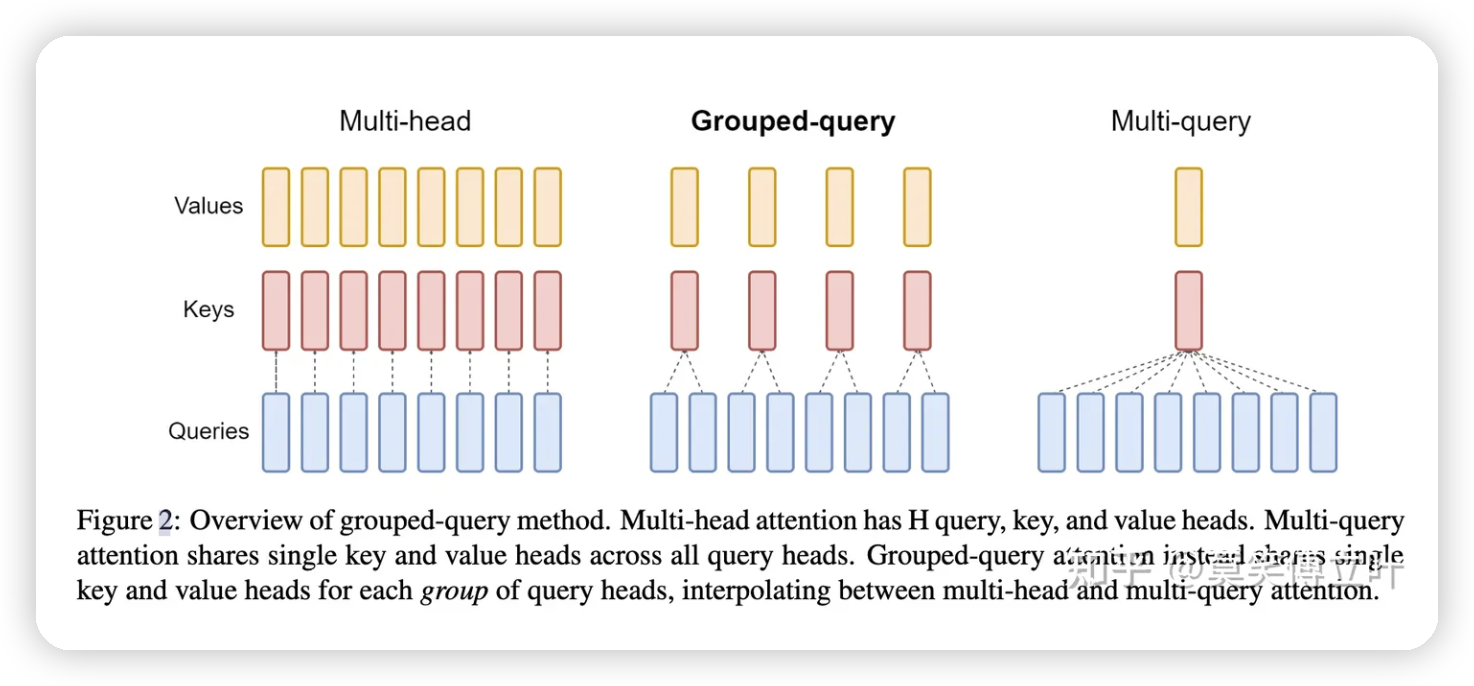
分组查询注意力将查询头分成 G 组,每组组共享单个键头和值头。GQA-G 是指 G 组分组查询。GQA-1,具有单个组,因此单个键和值头,相当于 MQA,而 GQA-H,组等于头数,相当于 MHA。在将多头检查点转换为 GQA 检查点时,通过平均池化该组内的所有原始头来构建每个组键和值头。
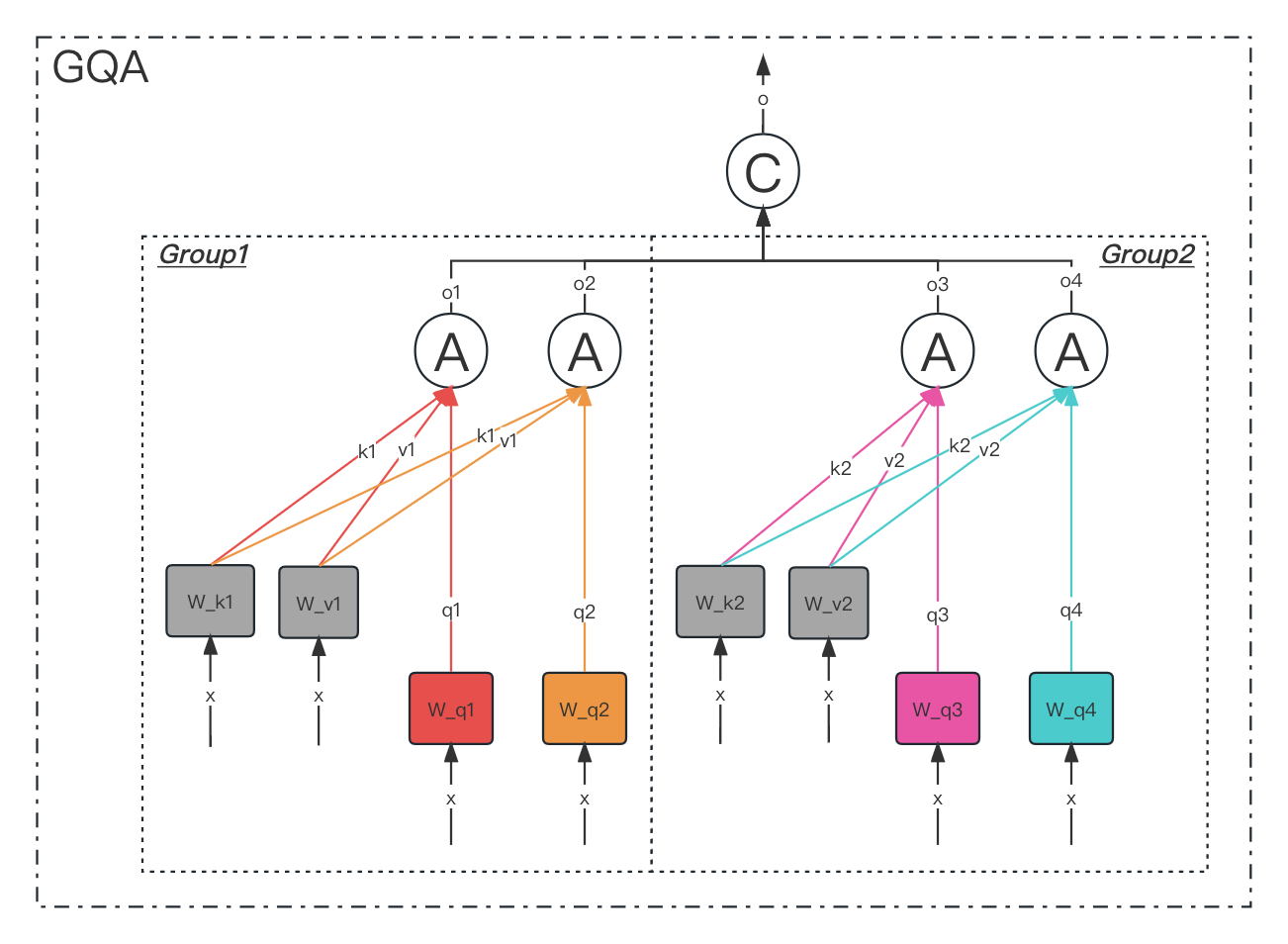
中间组数导致插值模型的质量高于 MQA,但比 MHA 更快。从 MHA 到 MQA 将 H 键和值头减少到单个键和值头,减少了键值缓存的大小,因此需要加载的数据量 H 倍。然而,较大的模型通常缩放头部的数量,使得多查询注意力在内存带宽和容量方面都代表了更积极的切割。GQA 允许随着模型大小的增加保持相同的带宽和容量比例下降。
